In this work, we present DINeMo, a novel neural mesh model that is trained with no 3D annotations by leveraging pseudo-correspondence obtained from large visual foundation models. We adopt a bidirectional pseudo-correspondence generation method, which produce pseudo correspondence utilizing both local appearance features and global context information.
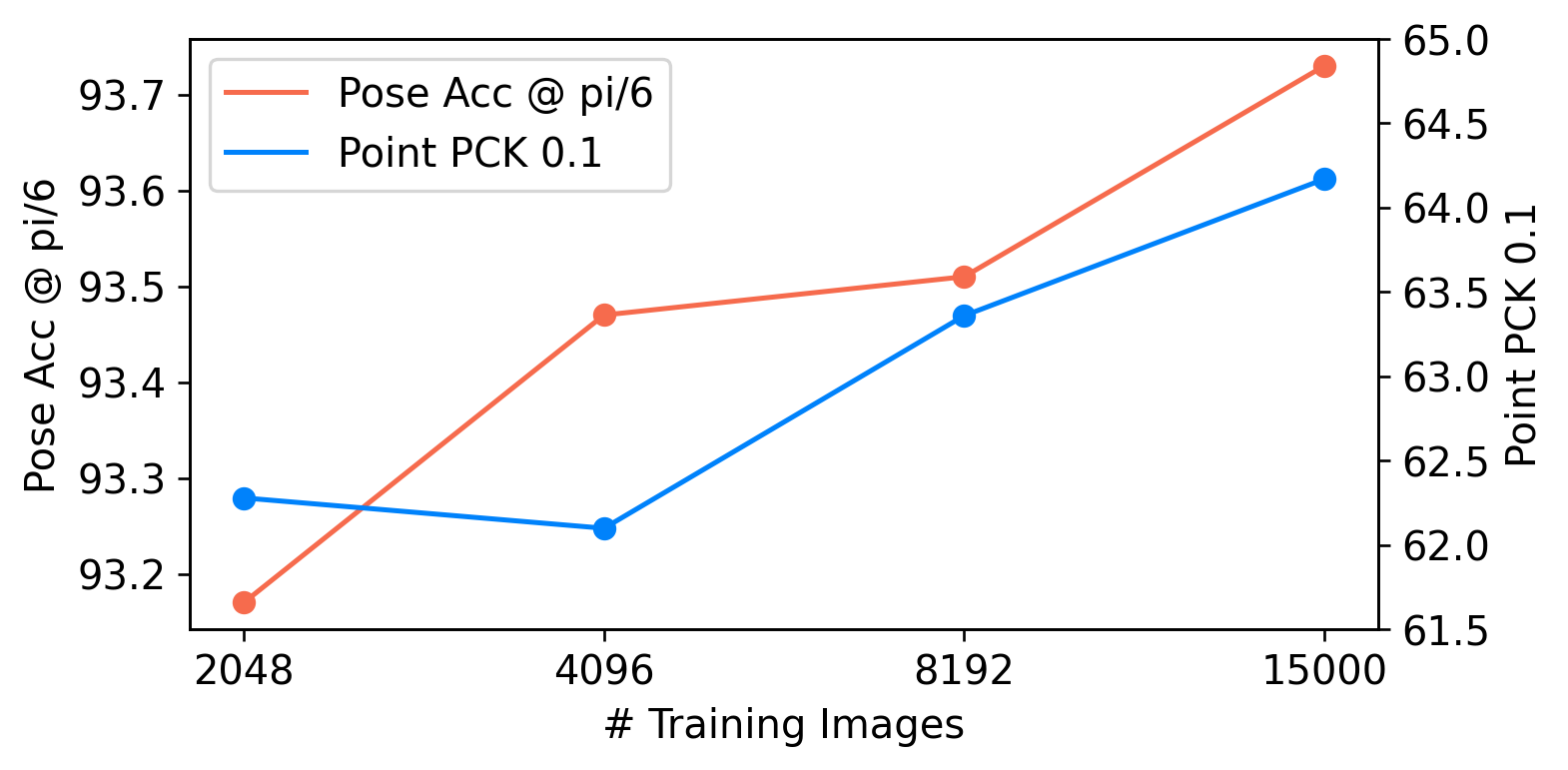
Experimental results on car datasets demonstrate that our DINeMo outperforms previous zero- and few-shot 3D pose estimation by a wide margin, narrowing the gap with fully-supervised methods by 67.3%. Our DINeMo also scales effectively and efficiently when incorporating more unlabeled images, which demonstrate the advantages over supervised learning methods that rely on 3D annotations.
DINeMo
Preliminaries. Neural mesh models
This allows us to predict object category
Our approach. Our goal is to exploit pseudo-correspondence obtained from large visual foundation models, such as DINOv2
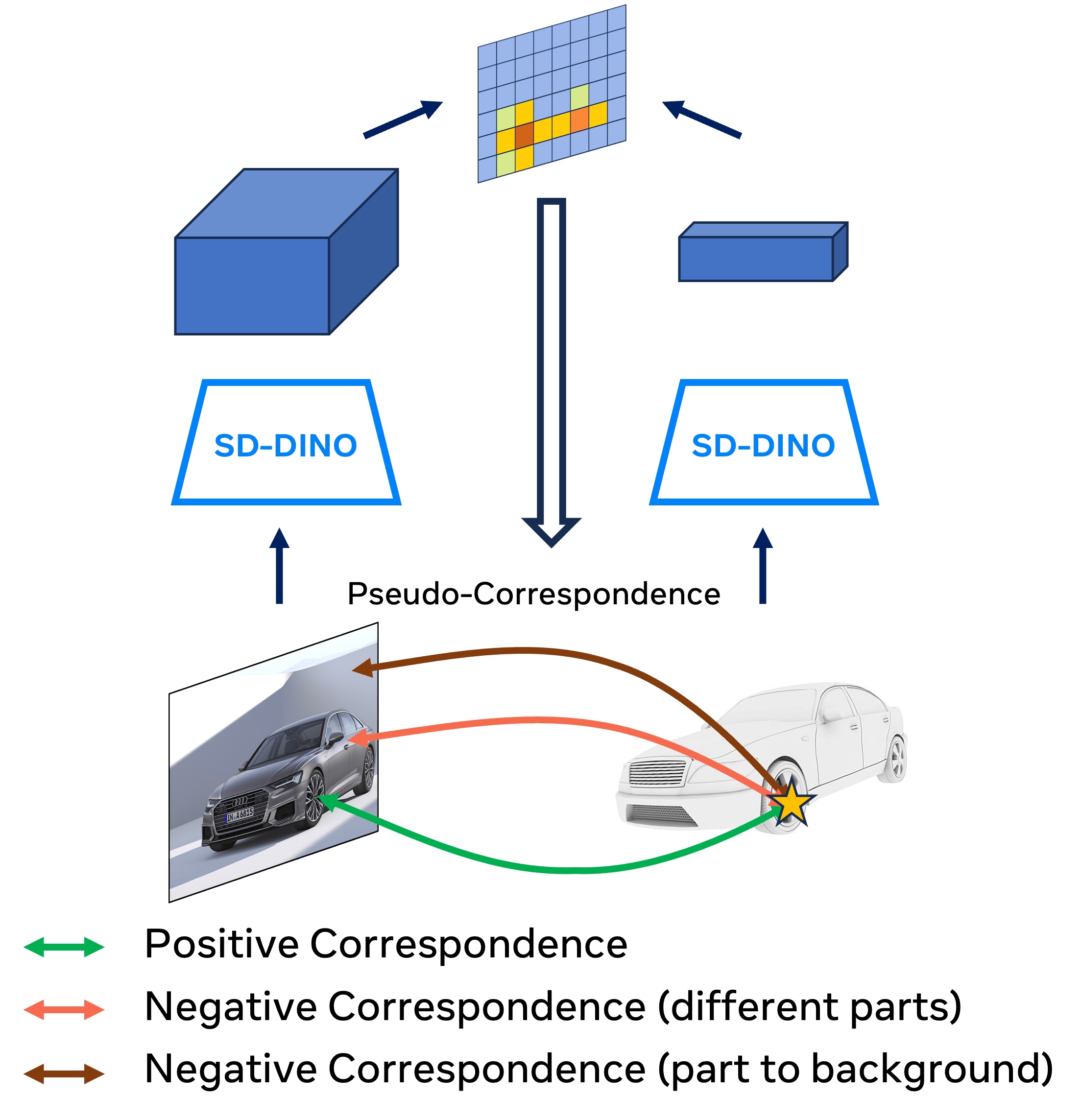
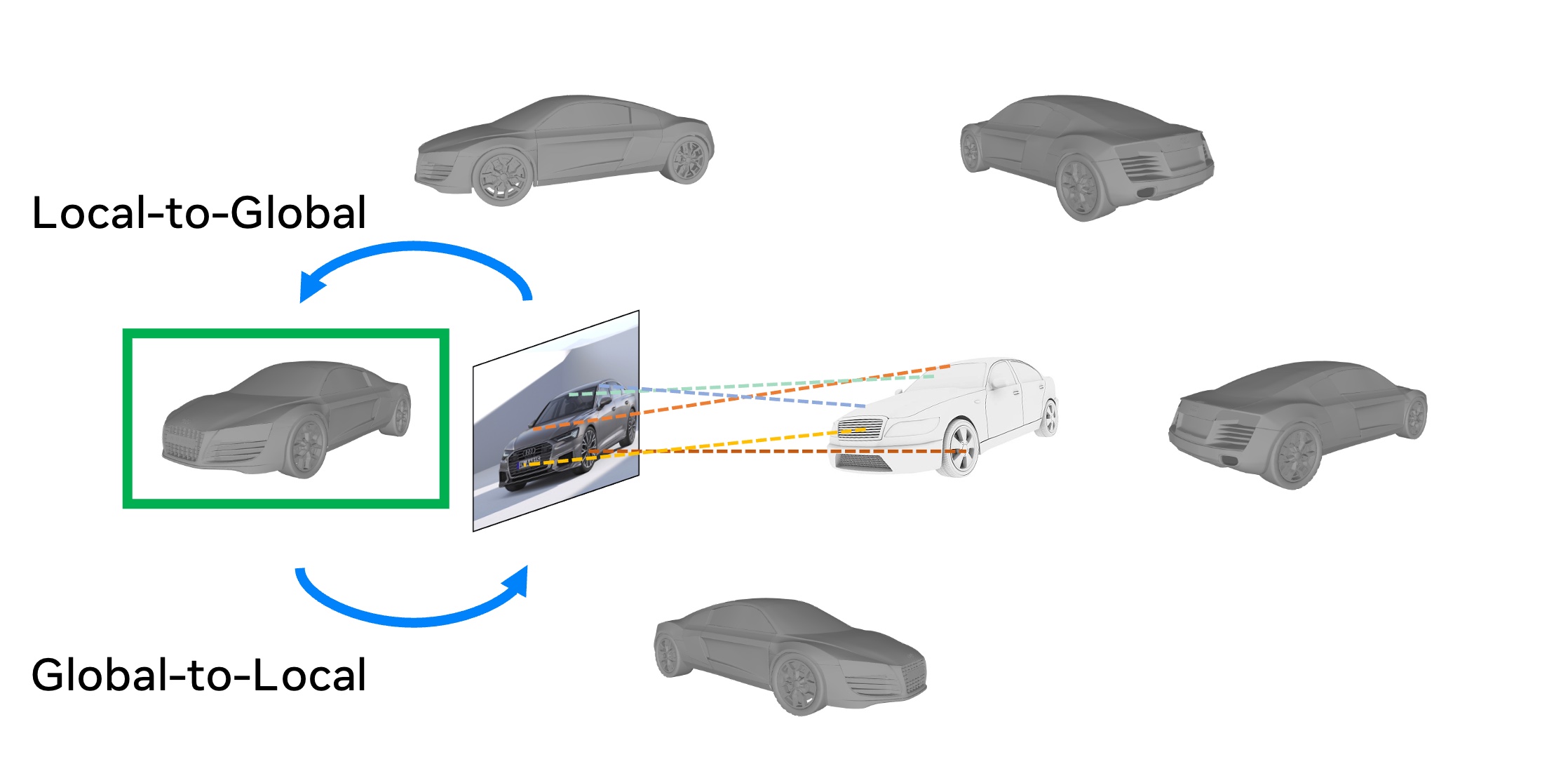
Bidirectional pseudo-correspondence generation. We find that raw pseudo-correspondence can be quite noisy, e.g., keypoints are often mismatched between left and right. We argue that keypoint correspondence matching should consider both local information, i.e., per patch feature similarities, and global context information, i.e., 3D orientation of the object. Based on this motivation, we propose a novel bidirectional pseudo-correspondence generation, which consists of two steps: (i) matching a global pose label from raw keypoint correspondences, and (ii) refine local keypoint correspondences based on the predicted global pose label.
Occlusion-aware analysis-by-synthesis. Previous neural mesh models adopt explicit occlusion reasoning during inference. However, directly predicting occlusion from neural features yields noisy masks and hurts final performance. With the recent rise of foundation models like Segment Anything
Main Results
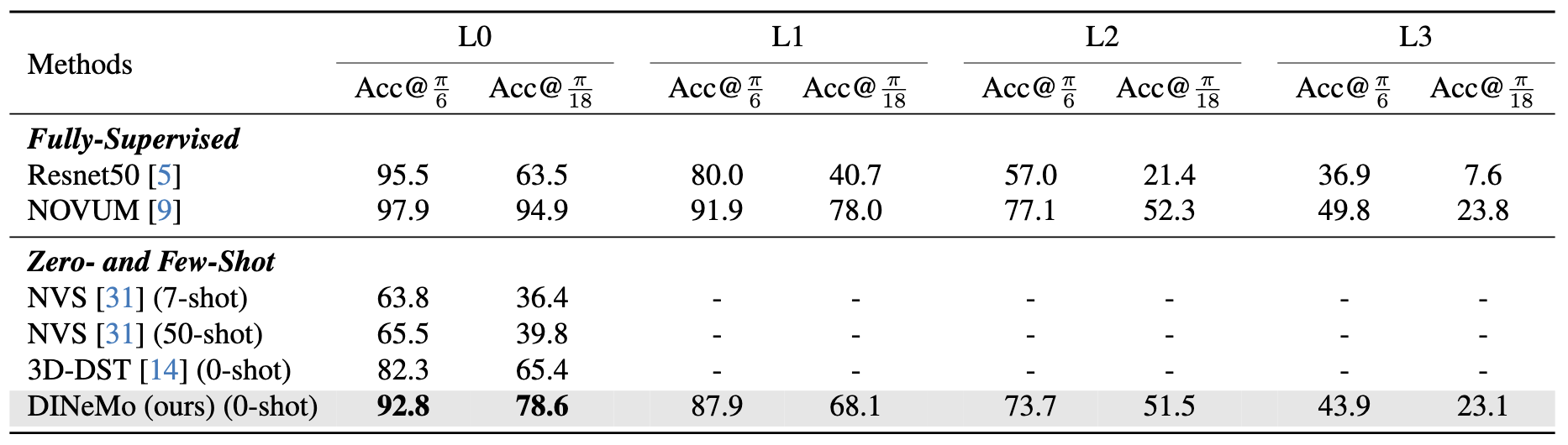
3D object pose estimation on the car split of Pascal3D+ and occluded PASCAL3D+.
Semantic correspondence evaluation on car split of SPair71k. Our DINeMo outperforms all previous methods by a wide margin and achieves comparable performance with Telling Left from Right 
Scaling properties of DINeMo with more unlabled object images used for training.
Qualitative Examples
Qualitative comparisons with and without our bidirectional pseudo-correspondence generation.

Qualitative comparisons between DINOv2 and our DINeMo on SPair71k dataset.

Qualitative pose estimation results on PASCAL3D+ dataset.
